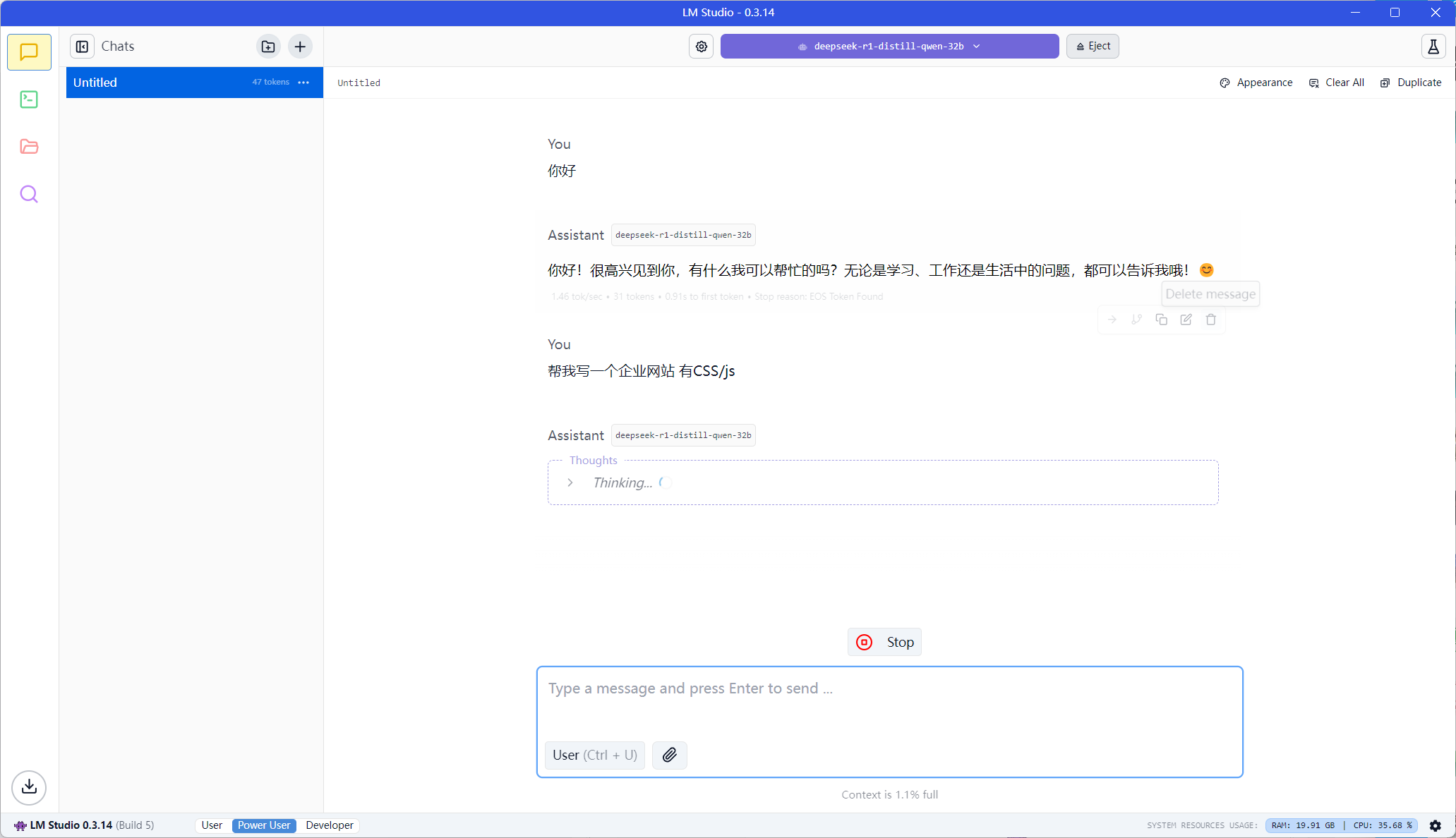
DeekSeek全版本模型,部署教程 1.5b,7b,8b,14b,32b,7
DeepSeek是由杭州深度求索人工智能基础技术研究有限公司研发的新一代通用人工智能大模型。该模型通过融合Transformer-XL架构与动态稀疏激活技术,构建了基于大规模自监督学习的预训练体系。其创新性的课程学习(Curriculum Learning)策略,使模型能够从PB级多模态数据中渐进式构建知识表征,较传统监督学习方法减少86%的标注依赖,同时在GLUE基准测试中取得89.7的综合得分。
值得关注的是,DeepSeek v2.0在模型效率方面实现重大突破:通过混合精度训练与模型并行优化,其千亿参数规模的训练成本较国际同类模型降低约40%,在MMLU(大规模多任务语言理解)评估中以82.3分超越GPT-3.5 Turbo(78.9分)。作为全球首个完整开源千亿参数商用级AI模型,DeepSeek不仅提供API接口和本地化部署方案,更开放了完整的训练日志与超参数配置。
下载地址
123网盘:https://www.123912.com/s/ekeA-5nG4
此外其开源的特性,让每个人都有可能部署一个私人的应用。
模型选择
| 模型名称 | CPU 配置 | 内存需求 | 硬盘需求 | 显卡需求 | 典型应用场景 |
|---|---|---|---|---|---|
| DeepSeek-R1-1.5B | 4 核+(推荐多核 Intel/AMD) | 8GB+ | 3GB+(约1.5-2GB) | 非必需,可选 4GB+ 显存(如 GTX 1650) | 树莓派/旧笔记本/物联网设备等低资源环境 |
| DeepSeek-R1-7B | 8 核+(现代多核 CPU) | 16GB+ | 8GB+(约4-5GB) | 推荐 8GB+ 显存(如 RTX 3070/4060) | 中小企业文本摘要/翻译/轻量对话系统 |
| DeepSeek-R1-8B | 8 核+(现代多核 CPU) | 16GB+ | 8GB+(约4-5GB) | 推荐 8GB+ 显存(如 RTX 3070/4060) | 代码生成/逻辑推理等需高精度轻量任务 |
| DeepSeek-R1-14B | 12 核+ | 32GB+ | 15GB+ | 16GB+ 显存(如 RTX 4090/A5000) | 企业级长文本理解与生成 |
| DeepSeek-R1-32B | 16 核+(i9/Ryzen 9) | 64GB+ | 30GB+ | 24GB+ 显存(如 A100 40GB/双 RTX 3090) | 专业领域高精度任务/多模态预处理 |
| DeepSeek-R1-70B | 32 核+(服务器级) | 128GB+ | 70GB+ | 多卡并行(如 2x A100 80GB/4x RTX 4090) | 科研机构/大型企业复杂生成任务 |
| DeepSeek-R1-671B | 64 核+(服务器集群) | 512GB+ | 300GB+ | 多节点分布式(如 8x A100/H100) | 超大规模 AI 研究/AGI 探索 |
如何使用?
首先下载LM studio(网盘里面有)
改变模型位置
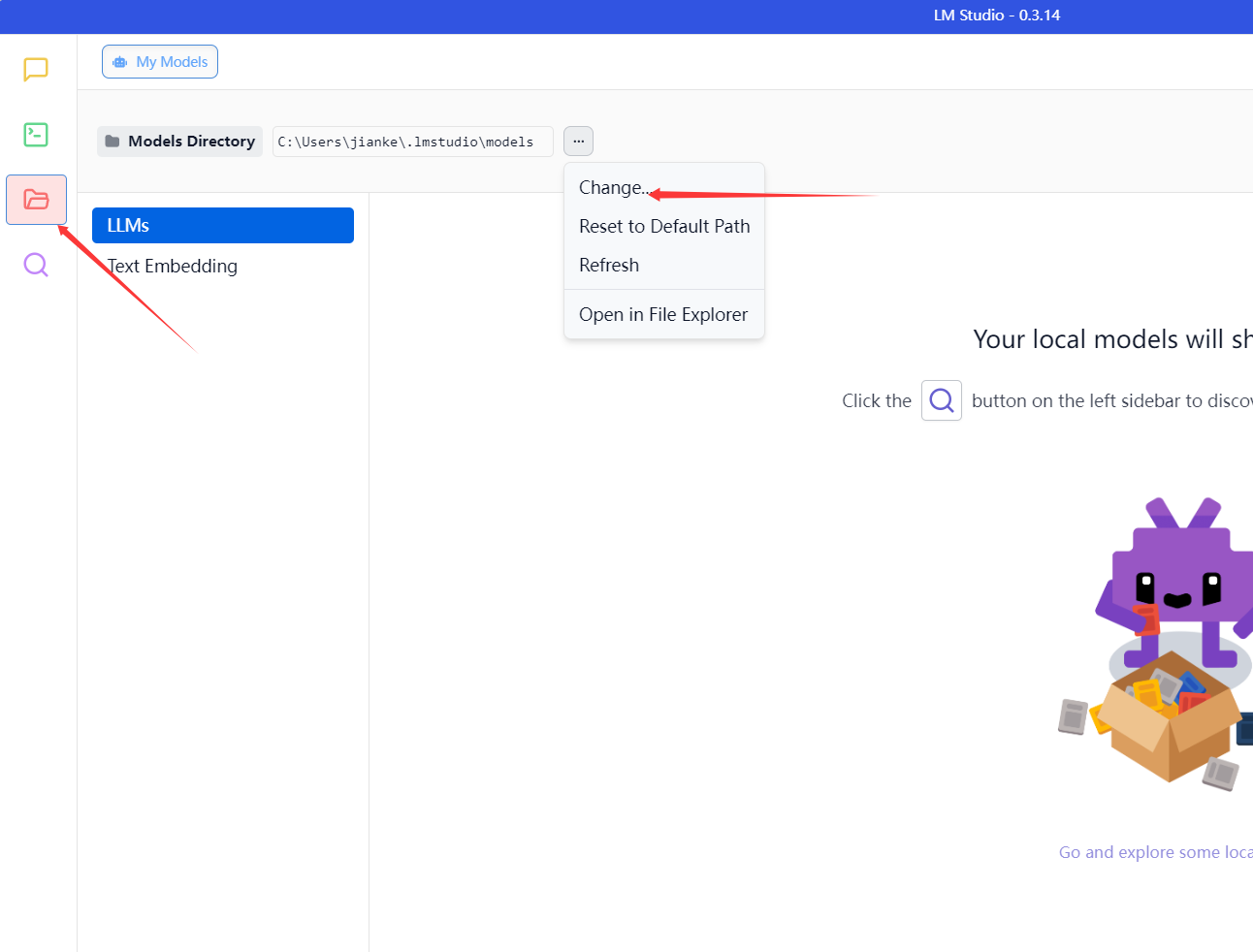
在选择路径下,创建“lmstudio-community”文件夹
拖动模型到刚刚创建的文件夹lmstudio-community内
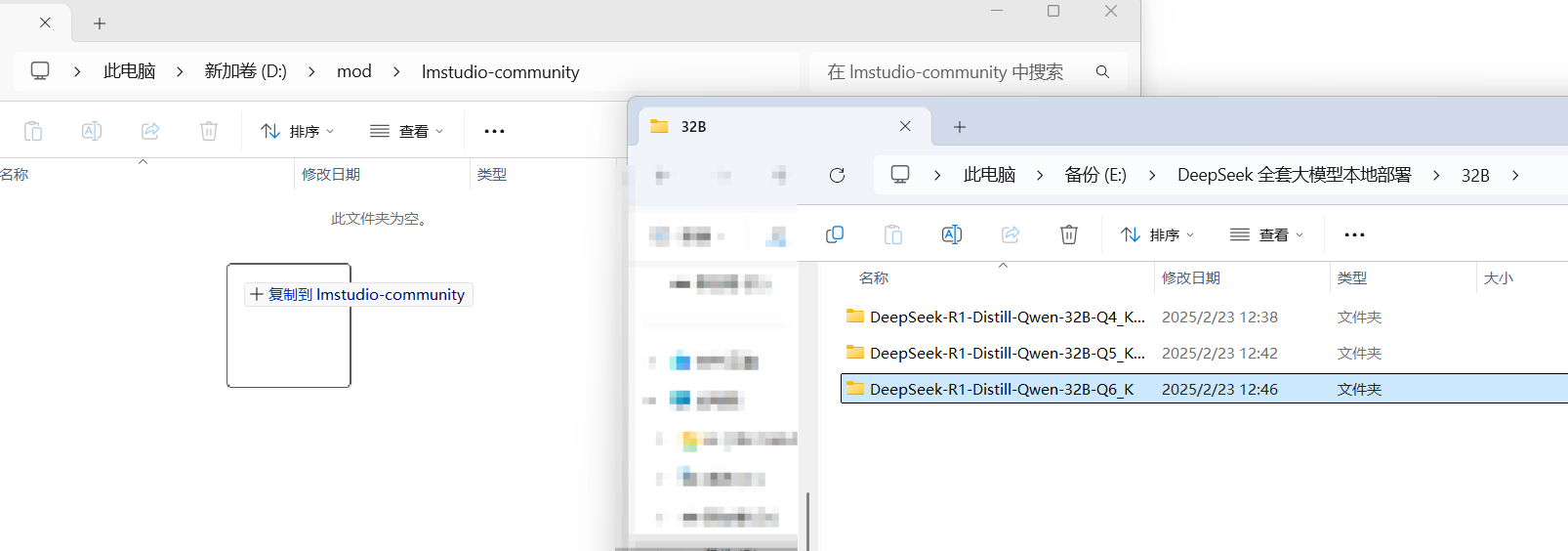
软件成功识别
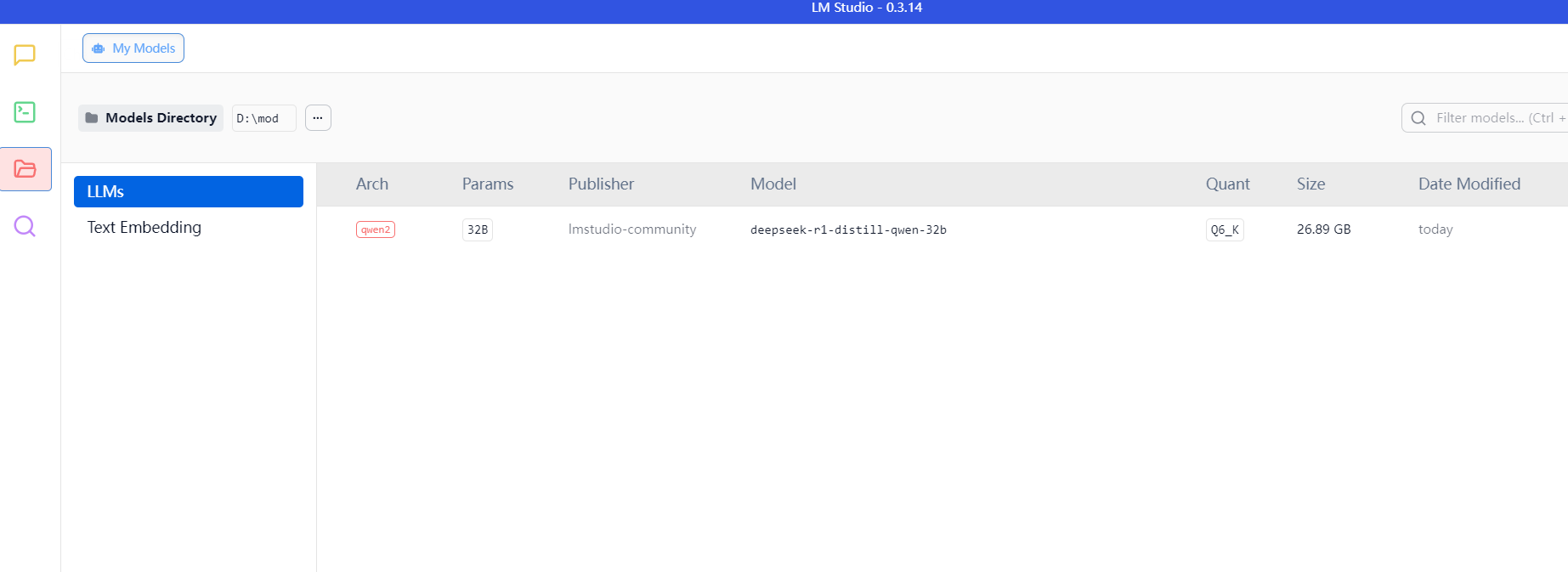
选择使用即可
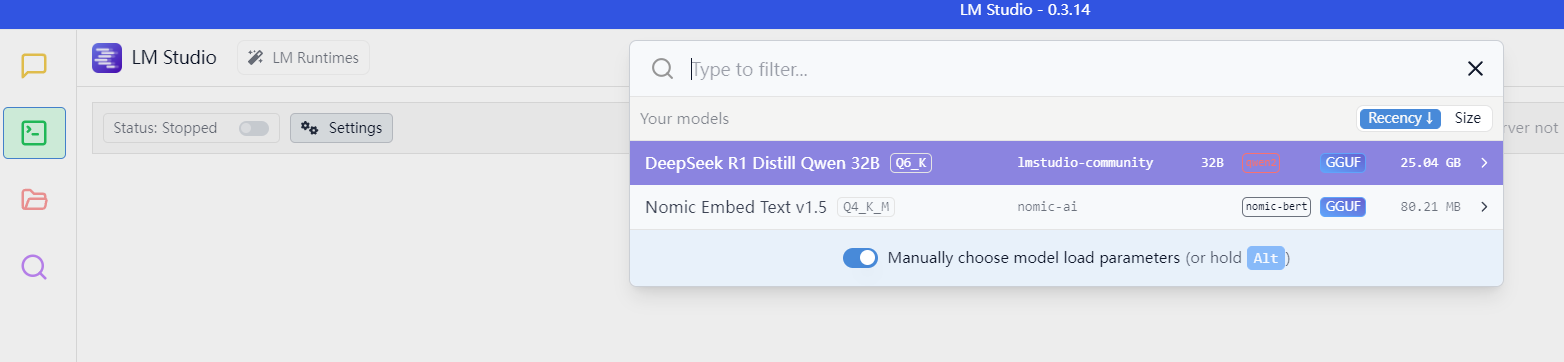
成功!